Comparer la puissance de deux ordinateurs, c’est facile !
Il y a une quinzaine d'années, quand on achetait un
nouvel ordinateur, on avait une idée assez précise de sa puissance. Cela
permettait aux gamers de comparer facilement leurs machines. De nos jours, c'est
beaucoup plus difficile, la puissance de calcul ne peut plus être calculée ou évaluée aussi aisément.
Voyons pourquoi.
Puissance et fréquence
Comment définir la puissance d'un ordinateur (ou d'une console de jeu, ou d'un
supercalculateur) ? Ce qui nous intéresse, c'est la quantité de travail qu'il est capable de traiter pendant un
certain temps. On mesure donc par exemple le nombre d'opérations effectuées par seconde, ce qui
ressemble à une vitesse.
Les opérations, qu'on appelle des instructions, peuvent être une addition ou une multiplication,
mais aussi une comparaison de deux nombres, une instruction conditionnelle permettant de choisir entre
deux traitements à effectuer, un renvoi vers une autre partie du code, et bien d'autres.Il y a une quinzaine d'années, on choisissait essentiellement son ordinateur en fonction de la fréquence de son processeur, c'est-à-dire le nombre d'instructions qu'il peut effectuer par seconde. Mon processeur à 100MHz était deux fois plus rapide que le processeur à 50MHz de mon voisin, car il pouvait traiter 100 millions d'opérations par seconde, deux fois plus que celui de mon voisin. La puissance des ordinateurs se résumait souvent à cette fréquence du processeur, approximation certes grossière, mais en général suffisante à cette époque.

puissance = fréquence
Mais la vitesse
d'exécution d'un programme donné dépend des opérations qu'il utilise. Elle peut donc varier fortement
d'un programme à l'autre, ce qui la distinguera de la puissance maximale théorique du processeur,
affichée par le constructeur et quasiment impossible à observer en pratique.Ça dépend des opérations
En pratique, la vitesse de traitement dépend du type d'opération que l'on confie au processeur. Ainsi, à la fin des années 90, on a vu apparaître sur le marché des processeurs MMX, dont le constructeur vantait les capacités multimédias. En effet, les programmes manipulant des données audio ou vidéo ont besoin de faire de nombreuses fois les mêmes calculs, par exemple sur chacune des images composant une vidéo. On a donc ajouté aux processeurs la faculté d'effectuer plusieurs additions ou plusieurs multiplications en même temps sur des données différentes (on parle de SIMD, Single Instruction Multiple Data). La puissance devient alors la fréquence multipliée par le nombre d'opérations que le processeur peut effectuer en même temps (de l'ordre de 4 ou 8 de nos jours).
puissance = fréquence × nombre d'opérations simultanées
Si on développe un programme de façon à utiliser plusieurs additions ou plusieurs multiplications à peu
près au même moment, le compilateur pourra les regrouper afin que le processeur les exécute d'un seul
coup, et donc beaucoup plus vite. Si par contre, peu d'additions ou de multiplications sont utilisées, mais que
d'autres opérations sont à effectuer au même moment, l'exécution ne sera pas accélérée. On constate en fait une
différence de plus en plus grande entre la puissance maximale vantée par les constructeurs et la puissance observée par les utilisateurs, c'est-à-dire la vitesse d'exécution d'un programme donné. Un programme doit être très
finement adapté aux capacités du matériel pour espérer en tirer des performances proches de sa
puissance maximale.Une autre façon d'accélérer l'exécution du programme a été d'ajouter des instructions plus complexes. Par exemple, certaines instructions actuelles peuvent calculer (a+b)*c d'un seul coup, deux fois plus vite que si on utilisait une addition puis une multiplication. D'autres instructions peuvent accélérer le chiffrage AES (par exemple pour la protection des réseaux wifi) ou effectuer le calcul des sommes de contrôle CRC (pour savoir si des données transitant sur Internet ont été corrompues) beaucoup plus rapidement que si elles étaient décomposées en opérations de base. En résumé, certains calculs peuvent être accélérés, d'autres peuvent être exécutés en même temps, d'autres non. La puissance de calcul observée dépend donc énormément du programme qu'on exécute (et du compilateur qui l'a traduit en langage machine).
Les processeurs multicœurs
L'avènement des processeurs multicœurs depuis une petite dizaine d'années a apporté un nouvel élément au calcul de leur puissance. En effet, chaque processeur contient désormais plusieurs cœurs dont les puissances sont combinées. La puissance totale d'un processeur devient donc sa fréquence multipliée par le nombre d'opérations pouvant être effectuées en même temps, puis multipliée par le nombre de cœurs.
puissance = fréquence × nombre d'opérations simultanées × nombre de cœurs
Les constructeurs ne s'y sont pas trompés, la fréquence est de moins
en moins mise en avant de nos jours. Alors que c'était le principal
argument de vente il y a une dizaine d'années, elle n'est presque plus
affichée dans les publicités
actuelles. En effet, elle varie peu d'un processeur à l'autre (entre 2
et 3 GHz en général). Par contre, le
nombre de cœurs peut varier d'un facteur 3 ou 4 entre deux processeurs,
il devient donc un argument
majeur de vente. Par exemple, un processeur à 6 cœurs à 2 GHz est censé
être 2 fois plus puissant qu'un
processeur à 2 cœurs à 3 GHz.
Mais cela n'est vrai que si le programme est capable de fournir du travail à tous les cœurs. Il y a 15 ans, un programme allait deux fois plus vite lorsqu'on passait d'un processeur 50 MHz à un 100 MHz. Aujourd'hui, passer d'un processeur de 2 à 4 cœurs ne garantit pas que notre programme ira deux fois plus vite. Si on lance quatre programmes en même temps, par exemple un traitement de texte, un navigateur web, un tableur et un lecteur de musique, ils pourront effectivement utiliser quatre cœurs différents en même temps. Par contre, un seul programme ne peut pas spontanément utiliser tous ces cœurs simultanément. Le concepteur devra d'abord le paralléliser, c'est-à-dire découper son algorithme en sous-parties indépendantes qui pourront être exécutées en même temps par différents cœurs. Dans le cas idéal, la répartition de ces parties permet au programme d'aller 4 fois plus vite en utilisant 4 cœurs. Mais en général, certaines portions du programme ne peuvent pas être découpées ainsi, elles ne seront donc pas du tout accélérées par la présence de plusieurs cœurs. La loi d'Amdahl, énoncée en 1967, clarifie ce phénomène. Elle montre que l'accélération apportée par les processeurs multicœurs est fortement limitée par la taille de ces portions non-parallélisables.
L'apport des processeurs multicœurs est donc clair en ce qui concerne la puissance théorique (elle est multipliée par le nombre de cœurs) mais ne garantit pas du tout un gain semblable pour la vitesse d'exécution d'un programme donné.
Une fréquence pas vraiment stable
Une autre raison d'accorder moins d'importance à la fréquence dans le calcul de la puissance est qu'elle varie fortement à l'intérieur d'un même processeur. C'est la consommation d'énergie qui est actuellement devenue le critère majeur décidant de la fréquence des processeurs. Selon la quantité de travail qu'on lui confie, le processeur va éventuellement se mettre en veille pour économiser de l'énergie. Il pourra notamment réduire fortement sa fréquence, parfois jusqu'à un facteur 3. En effet, la consommation d'énergie est proportionnelle à la fréquence. Heureusement, quand on lui confie à nouveau beaucoup de travail, il revient progressivement à sa fréquence maximale. On peut donc espérer que la fréquence reste maximale tant qu'on lui donne suffisamment de travail de faire.Là où cela se complique, c'est quand l'activité de certains cœurs joue sur la fréquence d'un autre. Si 3 des 4 cœurs sont en veille car ils n'ont pas de travail à faire, le quatrième pourra dépasser sa fréquence nominale et profiter de l'énergie que ses voisins n'utilisent pas (technologies comme TurboBoost ou TurboCore). Un cœur prévu pour fonctionner à 3 GHz pourra ainsi fonctionner entre 3 et 3,5 GHz selon l'activité de ses voisins. Ce phénomène ne compense cependant que légèrement la loi d'Amdahl, puisque 4 cœurs à 3GHz restent théoriquement beaucoup plus puissants qu'un seul à 3,5 GHz. Mais il contribue à rendre la puissance disponible difficile à mesurer.
En définitive, la puissance de calcul observée lors de l'exécution d'un programme dépend donc de sa façon d'utiliser le processeur, mais aussi des autres programmes s'exécutant sur cet ordinateur.
L'accès aux données, le maillon faible
Si la puissance est si difficile à mesurer en termes d'opérations effectuées, une autre solution consiste à mesurer la quantité de données que le processeur a traitées. Malheureusement, cette approche se heurte à la difficulté de calculer les temps d'accès aux données, qui dépendent eux aussi de nombreux facteurs.Les programmes manipulent des données qui sont stockées dans des fichiers sur le disque dur. Mais les processeurs ne peuvent pas directement les utiliser, ils doivent d'abord les charger en mémoire centrale (RAM), puis les mettre dans leurs propres cases mémoire, appelées des registres. Ces registres étant très coûteux, les processeurs n'en ont pas beaucoup. Les programmes doivent donc constamment transférer des données de la mémoire vers les registres, faire les calculs sur ces données, puis remettre celles-ci en mémoire.
La lenteur de la mémoire risque donc de ralentir considérablement les calculs, rendant la puissance du processeur inexploitable en pratique, car celui-ci doit attendre les données en provenance de la mémoire avant de pouvoir les utiliser dans ses calculs. Pour masquer ce problème, les processeurs récents sont capables de faire des calculs et des accès mémoire en même temps. On dit que les accès à la mémoire ne sont plus bloquants : le processeur peut demander le chargement d'une donnée en mémoire, exécuter les instructions suivantes (à condition qu'elles ne manipulent pas cette même donnée), puis revenir à l'instruction précédente quand la donnée demandée sera effectivement arrivée. Un changement d'ordre d'exécution des instructions permet donc au processeur de continuer à calculer à sa vitesse maximale pendant que d'autres instructions sont ralenties par la lenteur de la mémoire.
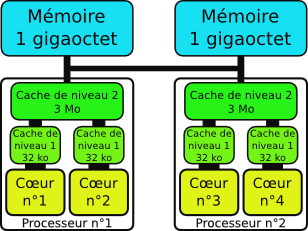
Machine bi-processeur bi-cœur. Chaque processeur contient un cache global et un cache par cœur.
Ainsi, le prefetcher observe les accès réalisés par vos programmes pour en déduire les prochains accès et donc aller chercher à l'avance les données. Par exemple, si un programme accède aux cases mémoire 3, 13 puis 23, le prefetcher va automatiquement rapatrier la case mémoire 33 dans le cache.
Tous ces mécanismes permettent au processeur de calculer sans avoir à trop souvent attendre les données en provenance de la mémoire, mais ce n'est pas infaillible.
Contention et effets de cache
Les caches permettent d'augmenter l'utilisation du processeur en lui évitant d'attendre la mémoire centrale (RAM), mais cela rend le comportement des machines difficile à prédire. Par exemple, si on veut savoir dans combien de temps un calcul va se terminer, il faut savoir quelles quantités de données il va lire dans le cache et dans la mémoire centrale. Si toutes ces données restent dans le cache, il se terminera bien plus vite que si elles sont toutes en mémoire centrale. Mais il est difficile pour un programmeur de savoir à l'avance quelle donnée le matériel va décider de garder dans ses caches.Pire, ce comportement varie d'une exécution à l'autre. La première exécution d'un programme devra aller chercher des données dans la mémoire centrale, elle sera donc lente. Par contre, si on relance le même programme peu après, les données ayant été chargées dans le cache par la première exécution peuvent encore s'y trouver. La deuxième exécution est donc plus rapide ! Cependant, si la deuxième exécution n'a pas lieu sur le même cœur, les données ne seront pas dans le bon cache. Le programme devra alors encore une fois aller les chercher jusqu'en mémoire centrale.
Encore pire, si deux programmes différents manipulent les mêmes données, elles peuvent êtres présentes dans les caches de deux cœurs distincts. En fonction des données utilisées par les autres programmes, la vitesse des accès aux données peut changer. En effet, si un premier programme modifie des données utilisées par un second, le processeur doit veiller à ce que les modifications du premier soient bien répercutées dans le cache du second. En pratique, le second devra attendre avant de pouvoir les utiliser, et les programmes s'exécutent alors tour à tour au lieu de simultanément, ce qui réduit l'intérêt des processeurs multicœurs.
Un domaine de recherche
Le temps où on connaissait précisément la vitesse d'exécution des programmes est révolu. Il n'existe plus de formule simple pour estimer la performance réelle d'un ordinateur. Multiplier le nombre de cœurs par la fréquence n'est pas une bonne approximation. La vitesse d'exécution s'éloigne de plus en plus de la puissance théorique annoncée par les constructeurs, car elle dépend des instructions que ce programme utilise, de la façon dont il a été compilé en code machine, et des programmes exécutés en même temps sur les cœurs voisins.Pour utiliser au mieux les ressources d'un ordinateur et espérer en exploiter au mieux les performances, le programmeur doit en connaître les capacités et y adapter son programme. Cela consiste notamment à paralléliser son programme pour utiliser les différents cœurs. Malheureusement, la parallélisation reste un problème difficile, car le découpage en parties indépendantes se heurte aux dépendances entre ces sous-parties. Impossible par exemple d'exécuter sur un second cœur un traitement qui utilise un résultat encore en cours de calcul sur le premier cœur. La parallélisation automatique est espérée depuis longtemps mais reste encore aujourd'hui un sujet de recherche. Les développeurs doivent toujours mettre la main à la pâte.
Une autre solution consiste à modifier la façon dont on programme les calculs, pour ne pas les paralléliser directement, mais simplement expliciter les dépendances entre les différentes sous-tâches. Une fois les dépendances déterminées, un logiciel pourrait alors automatiquement distribuer les sous-tâches parmi les cœurs. De nombreuses recherches sont actuellement menées pour définir les futurs langages de programmation pour ce modèle, les algorithmes utilisés pour la répartition des tâches, et les logiciels les implémentant. Cependant, cette approche impose d'avoir à l'avance une idée approximative de la durée d'exécution des tâches afin d'anticiper leur répartition, à la manière d'un diagramme de Gantt pour la gestion de projet. Elle se heurte donc au problème exposé ici : connaître la vitesse d'exécution des différentes tâches est devenu un vrai casse-tête !
-------------------------------------------------------------------------------------------------------------
Configuration Workstation Bi processor Nvidia maximus AMÉLIORER
_______________________________________________________________________________
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

